
HaspMap和HashTable区别

☀1.同步性
HashTable是同步的,线程安全的。
里面所有的方法,isEmpty(),isSize(),contains(),get()方法都加了synchronized关键字进项同步。所以效率很低。


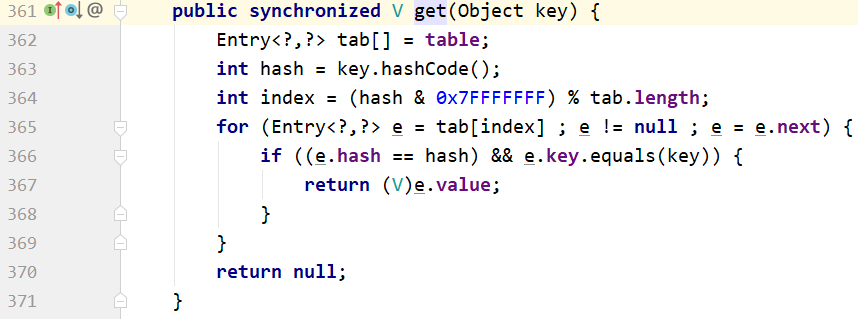

HashMap是线程不安全的。所以效率高。
综合效率和安全,所以我们通常亏考虑oncurrentHashMap,不会把整个方法全部锁住,会采用分段锁的方式。进项数据的锁定。
☀2.继承的父类不同。
回答面试官的时候,可以说看过,知道他们继承了不同的父类,是什么父类忘了。
HashTable继承了Distionary.

HashMap继承了AbstractMap.

☀3.对于Null Key和Null Value的支持不同
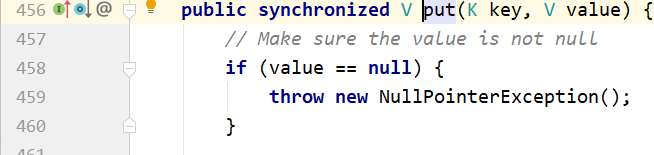
针对put方法而言的。
HashTable,的value会有非空判断。key如果是空也会报空指针。
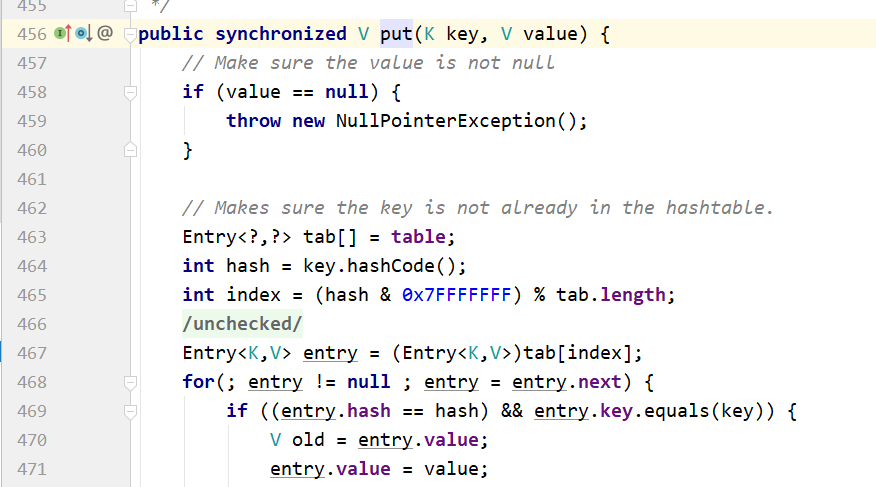
HashMap允许为空,判断key为null的时候,就将hash值之设为0。不为null就计算实际的hash。


☀4.遍历方法不同:
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
HashTable
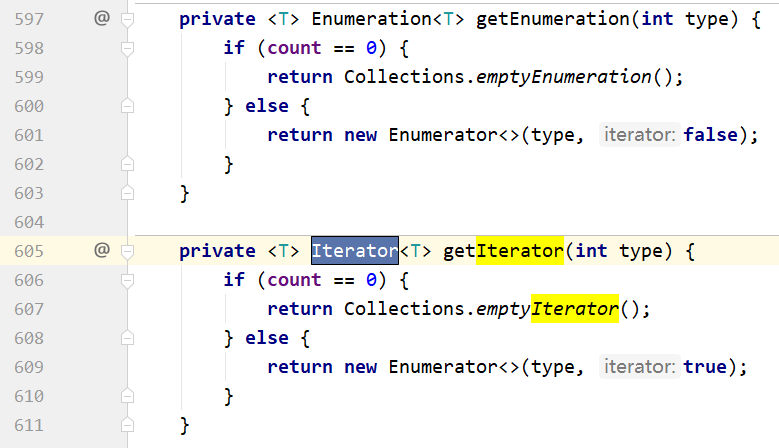
迭代器都是先判断有没有下一个。取出下一个。
☀5. 内部实现使用的数组初始化和扩容方式不同
☀内部初始化:
HashTable默认初始化使用11.在调用构造方法的时候就初始化了数组。

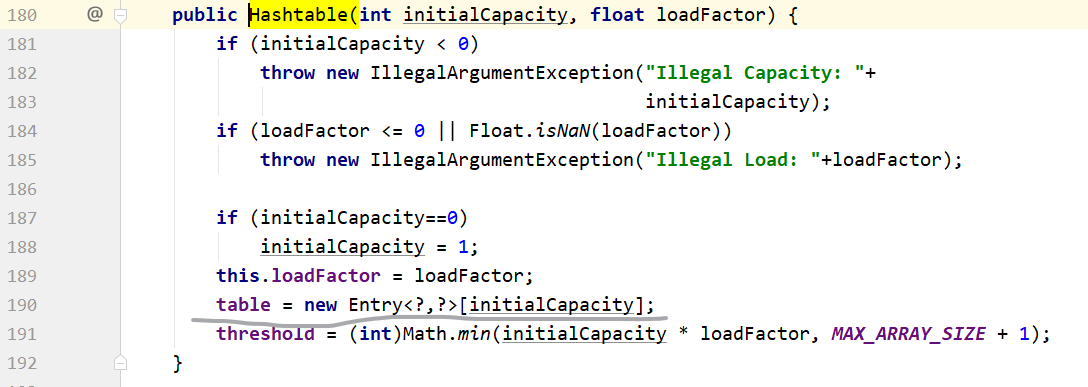
HashMap构造方法不会进行初始化。初始化值为16。
第一次调用put的时候,才会开辟出数组,进行存储。

重新扩充的方法里

进行初始化构建数组。

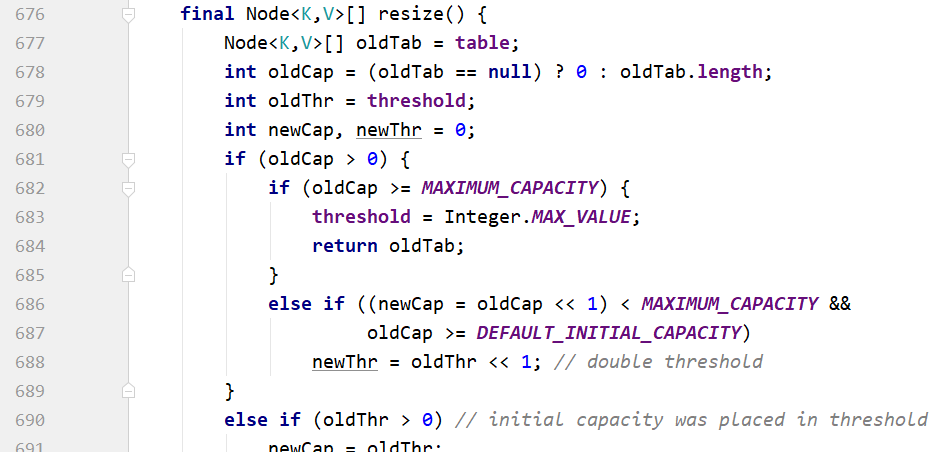
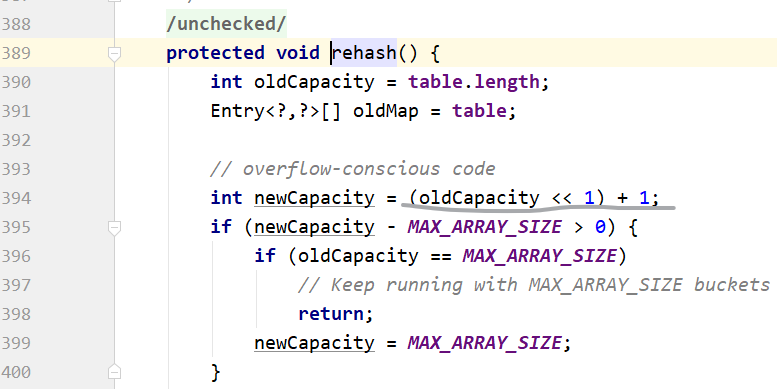
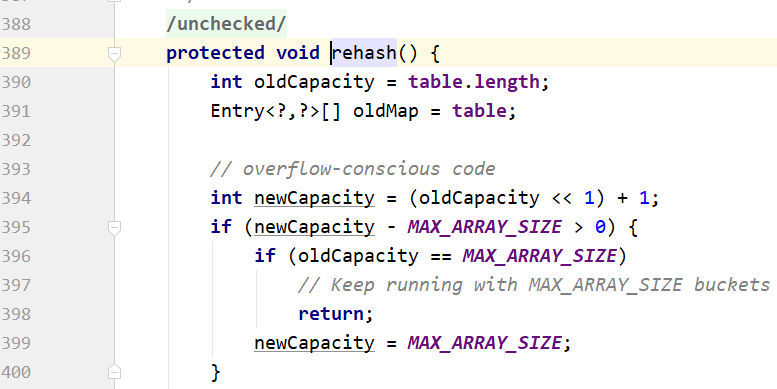
☀扩容:
HashMap
扩容是原来的两倍。HashMap处处体现考虑了效率,使用位运算比x2快。2是整数,需要转换为二进制才能运算,转换的过程耗费资源。
HashTable
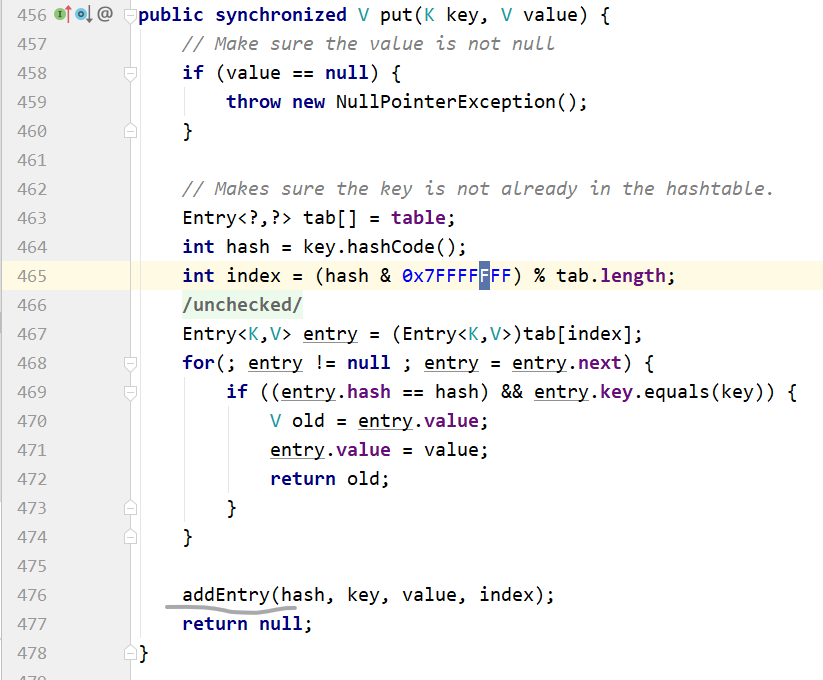
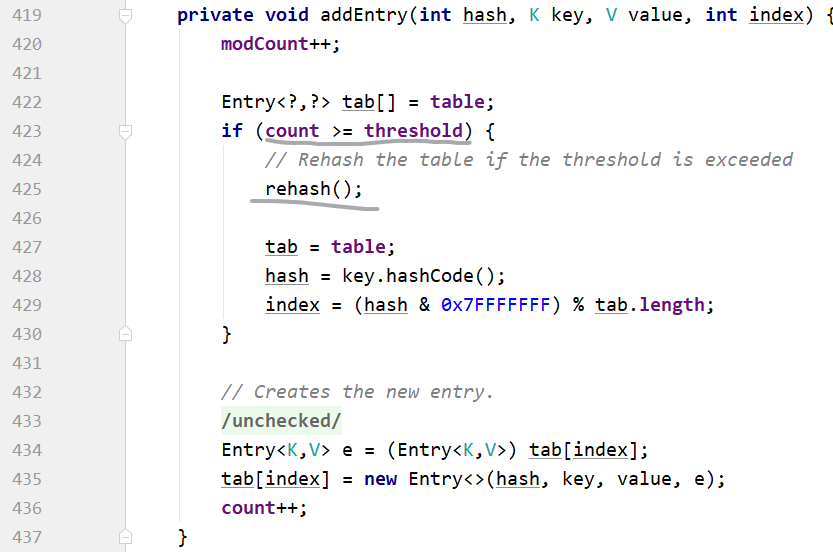
2倍+1.
☀6.计算hash值和下标的方法不同
HashMap
如果key是null则哈希值为0,如果不为0,是字符串的hash方法,是对象是对象本身的hash方法,计算出一个值,高16位向低16位右移,右移16位,高位和爹日同时参数与异或运算,计算出一个新的hash值。为什么右移16位,是int值,int是32位,使得高位参与运算,避免某些hash值计算结果频繁出现在高位。使得分布均匀。


下标的计算:
容量减一参与下标计算。与当前的hash进行与运算。

所以HashMap容量必须保证是2的次幂。
初始化构造方法的时候使用tableSizeFor。

初始化容量可以填任意一个参数。都能够算出离得最近的2的次幂。

HashTable

下标的计算:
将hash的符号位舍去(hash & 0x7FFFFFFF),取余数.其实int就是32位最大容量-1。
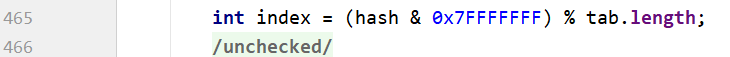
HashTable和HashMap理念上就是保留部分hash值的方法。
